2026年3月7日作成 / 2026年6月21日更新
多変量時系列データの異常検知のまとめ
AutoEncoder(オートエンコーダー)、マハラノビス法(Maharanobis method: MT法(Maharanobis Taguchi method)と呼ばれることもありますが、直交表を用いて特長量を絞り込む訳ではありませんので、本ページではマハラノビス法と呼びます)、Isolation Forest(アイソレーション・フォレスト) など、多変量時系列データの異常検知手法は多数提案されていますが、工場の操業データやサーバー運用データなど、複雑な多変量時系列データの実用的な予兆検知や異常検知手法として満足できる手法は殆ど無いのが現状です。本ページでは、このような予兆検知や異常検知の課題を指摘すると共に、その課題を克服した強力な実用的手法を提案します。
- 最先端の AutoEncoder は、時々刻々と変化する非線形な時系列データのどの部分に異常があるかを検知する手法としては優秀ですが、再構成誤差を使用しているため、窓幅という特定区間の予兆検知や異常検知手法としてはかなり精度が悪くなります。
- 古くから提案されている マハラノビス法は、窓幅という特定区間の多変量の予兆検知や異常検知手法としては優秀ですが、統計的手法ですので基本的に信号の非線形性、「位相」「トゲ」「周期性」などのズレを検知することはできません。
- 信号の非線形性、「位相」「トゲ」「周期性」などのズレを凝縮した AutoEncoder の特長量をマハラノビス法の入力に加えることにより、実用的な予兆検知や異常検知手法を構築することができます。
時系列データの予兆検知や異常検知に関する豊富な経験がございますので、ご質問やご相談がありましたら、ネオラクス・メール送信フォームからお気軽にお問い合わせください。
多変量時系列データの異常検知の現状
時系列データの異常検知 - マロッタバルブの異常検知 や 時系列データの異常検知 - 心電図の異常検知 に示す通り、1変量の異常検知であれば、1D-CNN による AutoEncoder を使用すれば、かなり実用的な異常検知モデルを構築することが可能です。
しかし、多変量時系列データの異常検知になると、1D-CNN による AutoEncoder は、チャンネル間の畳み込みが発生しないため効力を発揮できず、2026年現在の最先端の研究レベルでは以下のような方法が提案されています。
- Transformer による Anomaly Transformer(2022)(MIT License)
- 2D-CNN による TimesNet(2023)(清華大学の時系列ライブラリ TSLib で利用可能: MIT License)
- Fourier-KAN による KAN-AD(2025)(同上)
- Mamba と疎な Attention を組み合わせた MAAT(2025): License の記述無し - 問い合わせたが回答なし
CPU使用率、メモリ使用量、ネットワークスループットなど、合計 38次元 のメトリクスがある 28台のサーバー運用ログである SMD (Server Machine Dataset) データセットを使用してこれらの最先端の異常検知手法をテストした結果、TimesNet と KAN-AD が F1-score で 0.8 程度であり、MAAT が 0.9 程度でした。しかも、この数値は、殆どの論文で採用されている Point Adjustment (PA) というルールに基づいて計算されていますので、現実のレベルより高スコアになっている点に注意する必要があります。
多変量時系列データの異常検知における AutoEncoder の弱点
AutoEncoder では、一定の区間(窓幅)を一定量(1ステップ、半窓幅、全窓幅)ずらしながらデータを生成します(Sliding Window Algorithm: スライディン・グウィンド・アルゴリズム)。そして、多変量の AutoEncoder では、正常データのみで学習したチェックポイントを使用して、Encoder ⇒ Decoder を通すことにより、各時系列点の再構成誤差を予測し、これが閾値を超えたかどうかにより異常を判定します。
AutoEncoder は、「正常データのみ」を学習に使い、そこから外れたものを「異常」とみなすアプローチをとるため、機械学習(深層学習)の分類としては教師なし学習(Unsupervised Learning)、または半教師あり学習(Semi-supervised Learning)に位置づけられます。「正常データのみ」を学習に使っているので、「教師あり学習では?」と思う方もいらっしゃると思いますが、学習時に「これは正常」「これは異常」という正解ラベル(教師信号)を必要としないのでこのように分類されます。
実プロセスへの応用という面では、各時系列点の異常判定ももちろん重要ですが、それ以上に、一定区間(窓幅)で異常が発生したかという判定も重要になります。この際、前述の通り、殆どの論文では Point Adjustment (PA) というルールが適用されます。
図1 では区間B のみが異常が正解(Ground Truth)です。この図には、再構成誤差と異常判定の閾値(破線)も表示されていますが、区間B では 5点がこの閾値超えていますが、区間A と区間C では 1点のみしか超えていません。この場合、論文の PA を適用した異常の判定では、区間B は全区間異常、区間A と区間C では 1点のみ異常と判定されます。それぞれの区間の時系列データの点数が100点あるとすると、区間A と区間C では 1点のみ異常ですので 99% 正解となり、区間B は全区間異常ですので 100% 正解となります。
ところが、実際の操業データでは、どの区間が正常でどの区間が異常というラベルはついていませんので、再構成誤差により窓幅全体の正常/異常を判定すると大変な事態に陥ります。仮に、図1 のケースで、再構成誤差が 1回でも閾値を超えた区間(窓幅)を異常と判定した場合、区間A ~区間Cの全区間が異常という判定になりますので、正解率は 33% になってしまいます。論文値では99%以上の正解値をはじき出す高精度なモデルでも、実際の応用では 33% と、とてもかけ離れた値になってしまう訳なのです。
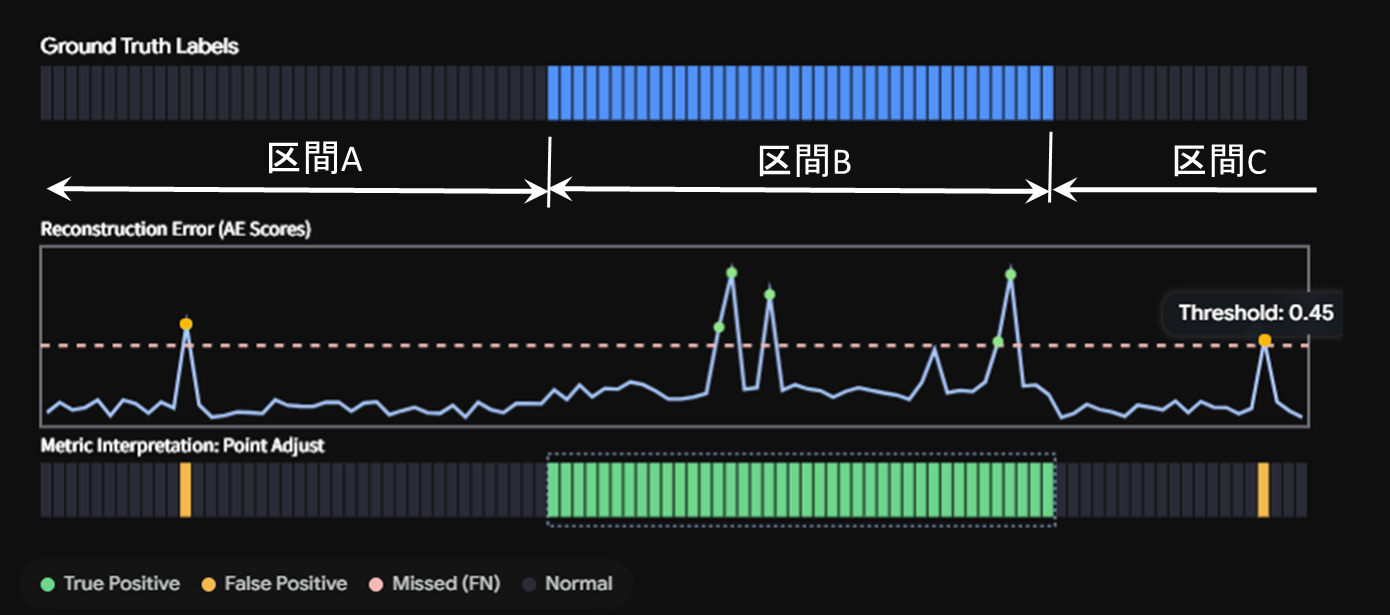
図1 AutoEncoder で異常検知が困難な理由
多変量時系列データの異常検知におけるマハラノビス法の弱点
通常、窓幅にマハラノビス法を適用する場合、変数ごとに窓幅全体の「平均値」「最大値」「標準偏差」などの統計的な特長量のみ使用します。即ち、 AutoEncoder と同様に時系列データにスライディングウィンドウは適用しますが、各センサーの統計量のみ使用しますので、AutoEncoder のような「位相」「トゲ」「周期性」などのズレに起因する異常判定はできません。
例えば、下図に示すセンサーA と センサーB の挙動は、全く異なることは一目瞭然ですが、比較対象のスライディング窓幅において「平均値」「最大値」「標準偏差」などの統計量は全く同じになってしまいますので、これらの信号をマハラノビス法で判別することはできません。また、窓のどの時点で異常が発生したかという判定もできません。
ちなみに、マハラノビス法は、「正常データのみ」の統計的性質を抽出してモデル化し、中心点からの距離(マハラノビス距離)を計算します。このため、機械学習の分類としては教師なし学習(Unsupervised Learning)に該当します。
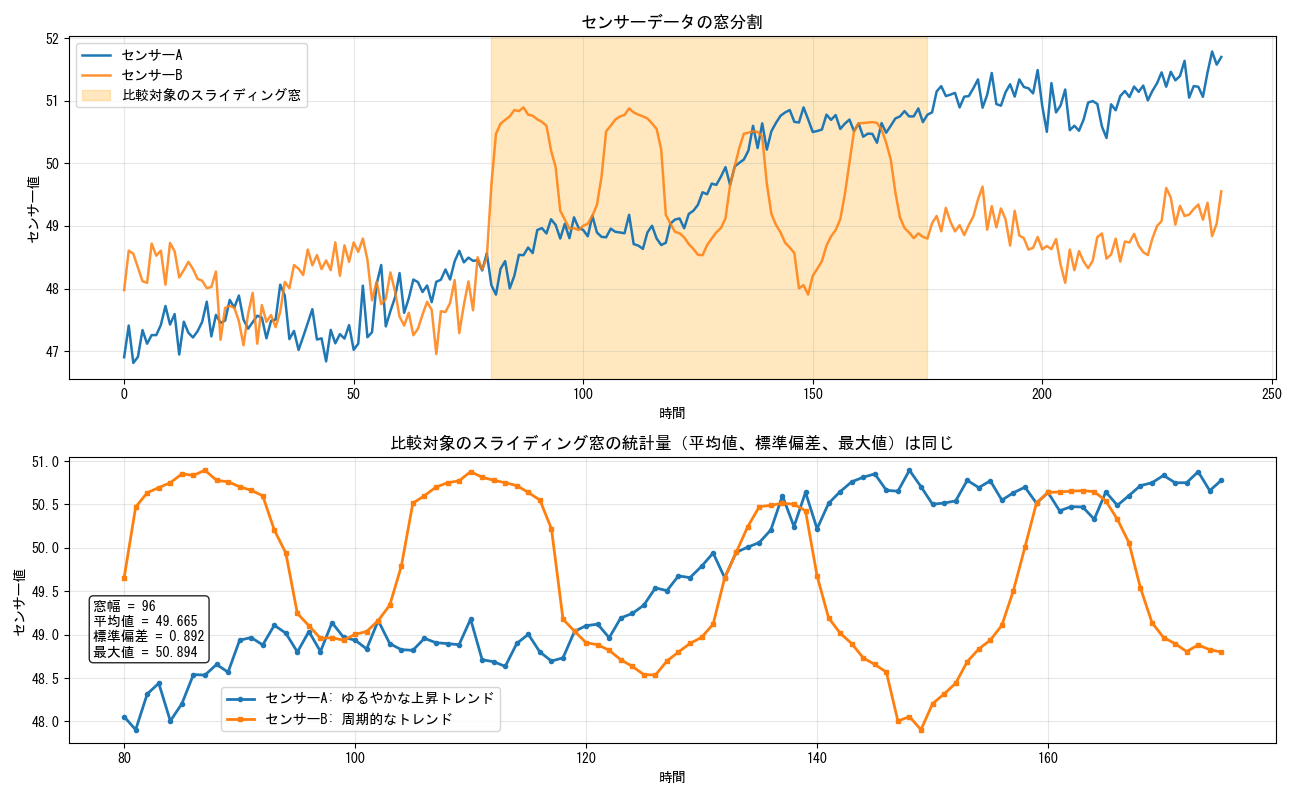
図2 マハラノビス法の弱点
多変量時系列データの異常検知手法の改良 - AutoEncoder + マハラノビス法
AutoEncoder の弱点と マハラノビス法の弱点を提示しましたが、これらの弱点は、窓幅全体の統計量を見ているマハラノビス法と、窓内の時系列情報を精密に見ている AutoEncoder でそれぞれの弱点を補完してやれば、最強の多変量時系列データの異常検知手法を構築することができます。
窓幅全体の正常/異常を判定する方法としては、Isolation Forest(2008) が効力を発揮するケースもありますが、ここでは多変量の相関の崩れを正確に捉えることができる マハラノビス法 をお勧めします。マハラノビス法は、相関係数行列( \(R\) )の逆行列を内積で挟み込む構造になっているため、変数が多くなっても相関の崩れを正確に捉えることができます。
時系列データの「位相」「トゲ」「周期性」などのズレは、 AutoEncoder の特長量(潜在変数)に凝縮されていますので、これらの特長量をマハラノビス法の特長量に加えればこれらの情報もマハラノビス法に取り込むことができます。この時、マハラノビス法の多重共線性(マルチコ: Multicollinearity)に対する不安定性を抑制するため、 AutoEncoder の特長量には PCA (主成分分析)を施すことをお勧めします。
ここで提案する AutoEncoder + マハラノビス法 は、「正常データのみ」を使用します。また、マハラノビス法が扱う特長量は AutoEncoder の潜在変数ですので、教師なし学習(Unsupervised Learning)の深層学習に分類されます。ちなみに、機械学習(Machine Learning)と深層学習(Deep Learning)の違いは、多層ニューラルネットワークを使用するかどうかの違いです。
図3は、 TimesNet 特徴量(64個)に PCA を施した時の主成分数と再現精度の関係を示したものです。主成分 16個でもある程度の再現性はあるようですが、主成分 16 個はマクロな周期(大枠のトレンド)の成分であり、主成分17個~32個はミクロな周期(「位相」「トゲ」「周期性」などのズレの高周波成分)の成分であることが多いため、主成分数は 32個程度にすることをお勧めします。
- 主成分 8 個に圧縮した場合の再現精度: 72.74 %
- 主成分 16 個に圧縮した場合の再現精度: 86.53 %
- 主成分 32 個に圧縮した場合の再現精度: 97.32 %
- 主成分 48 個に圧縮した場合の再現精度: 99.73 %
- 特徴量 64 個全てを使用した場合の再現精度: 100.00 %
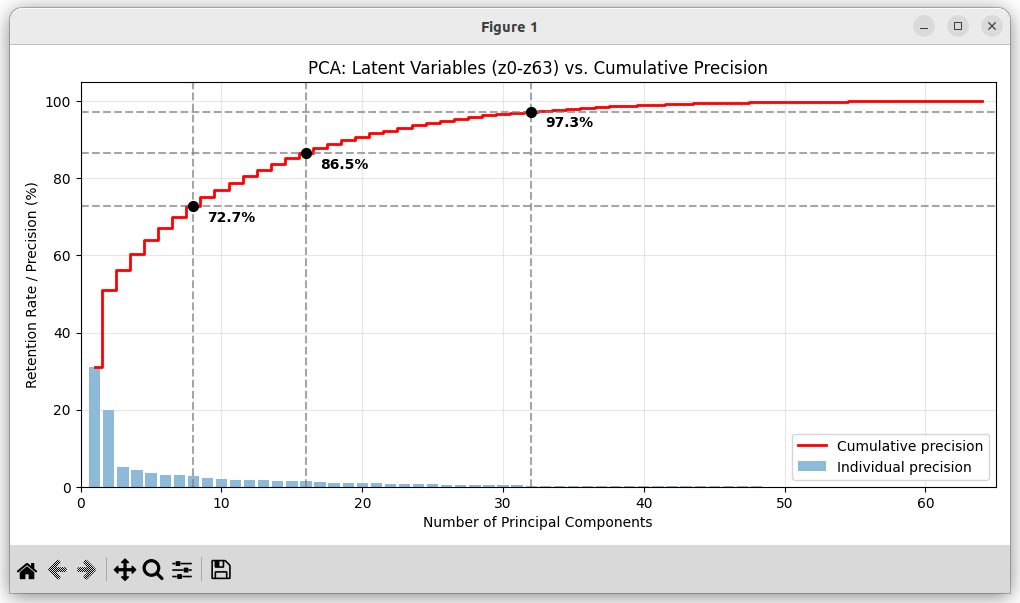
図3 TimesNet 特徴量の PCA 結果
異常検知の性能を見る指標の意味
-
Precision(精度・適合率) -「異常だと判定したもの」のうち、実際に異常だった割合
※「空振りの少なさ」を表します。$$P = \frac{TP}{TP + FP}$$ -
Recall(再現率) - 「実際に存在する異常」のうち、正しく検知できた割合
※「見逃しの少なさ」を表します。$$R = \frac{TP}{TP + FN}$$ -
F1-score - Precision と Recall の調和平均をとった指標
※ 両者はトレードオフの関係にあるため、総合的な評価に用います。$$F1 = \frac{2 \cdot P \cdot R}{P + R}$$
各変数の定義:
| TP (True Positive) | 異常を正しく「異常」と判定した数 |
|---|---|
| FP (False Positive) | 正常なのに「異常」と誤検知した数(空振り) |
| FN (False Negative) | 異常なのに「正常」と見逃した数(見逃し) |
| TN (True Negative) | 正常を正しく「正常」と判定した数 |
Point Adjustment (PA) について
時系列異常検知の論文を読む際、提示されているベンチマークの数値には注意が必要です。
多くの論文の値は Point Adjustment (PA) という 「異常期間のうち1点でも当てれば、その全期間(連続する異常セグメントすべて)を正解(TP)としてカウントし直す」 というルールに基づいて計算されています。
このルールを適用すると、実態よりも指標(特にRecallやF1)が極端に高く出やすくなり、実務での実力値(PAなしのPoint-wise評価)とかけ離れる原因になるため、評価の際はPAの有無を必ず確認する必要があります。
多変量時系列データの異常検知の課題解決方法
* 無断転載禁止。
* どのページでもご自由にリンクして下さい。
* ご意見・ご質問等がございましたら
こちらからメールをご送付下さい。
無料SEO対策
-172.31.37.45。